Modello di machine learning tradizionale (sperimentale)#
Scopri come utilizzare Xinference per inferire modelli di machine learning tradizionali. In Xinference, questi modelli flessibili e scalabili sono chiamati modelli flessibili.
Added in version v1.7.1: Questa funzionalità è pubblica dalla versione v1.7.1. Attualmente l’API non è stabile e potrebbe subire modifiche nelle successive iterazioni.
Introduzione#
I modelli di machine learning tradizionali possono ancora svolgere un ruolo importante nell’ecosistema incentrato sui modelli di grandi dimensioni.
Xinference offre capacità di estensione flessibili per l’inferenza di modelli di machine learning tradizionali. Supporta nativamente il caricamento e l’esecuzione dei seguenti tipi di modelli:
La HuggingFace Pipeline, che utilizza modelli ospitati su HuggingFace, può essere impiegata per attività come la classificazione.
Usando la ModelScope Pipeline per i modelli su ModelScope, può essere utilizzata per compiti come la classificazione.
YOLO è utilizzato per il rilevamento di immagini e attività correlate di computer vision.
Xinference supporta diversi modelli di machine learning tradizionali. Per ciascuna delle categorie sopra menzionate, dimostreremo passo dopo passo come eseguire l’inferenza sulla piattaforma Xinference, utilizzando un esempio rappresentativo.
Casi di supporto del modello integrato#
HuggingFace Pipeline modello#
Innanzitutto, prendiamo come esempio FacebookAI/roberta-large-mnli. Questo modello appartiene alla categoria dei modelli di classificazione zero-shot. Per altri tipi di modelli, durante la registrazione è sufficiente specificare il compito corrispondente (che è anche un parametro di Pipeline).
Scarica il modello nel seguente percorso:
/path/to/roberta-large-mnli
Successivamente, mostreremo come registrare il modello flessibile nell’interfaccia utente Web di Xinference. Negli esempi successivi, tranne quando necessario, salteremo le operazioni dell’interfaccia per concentrarci sulla logica centrale.
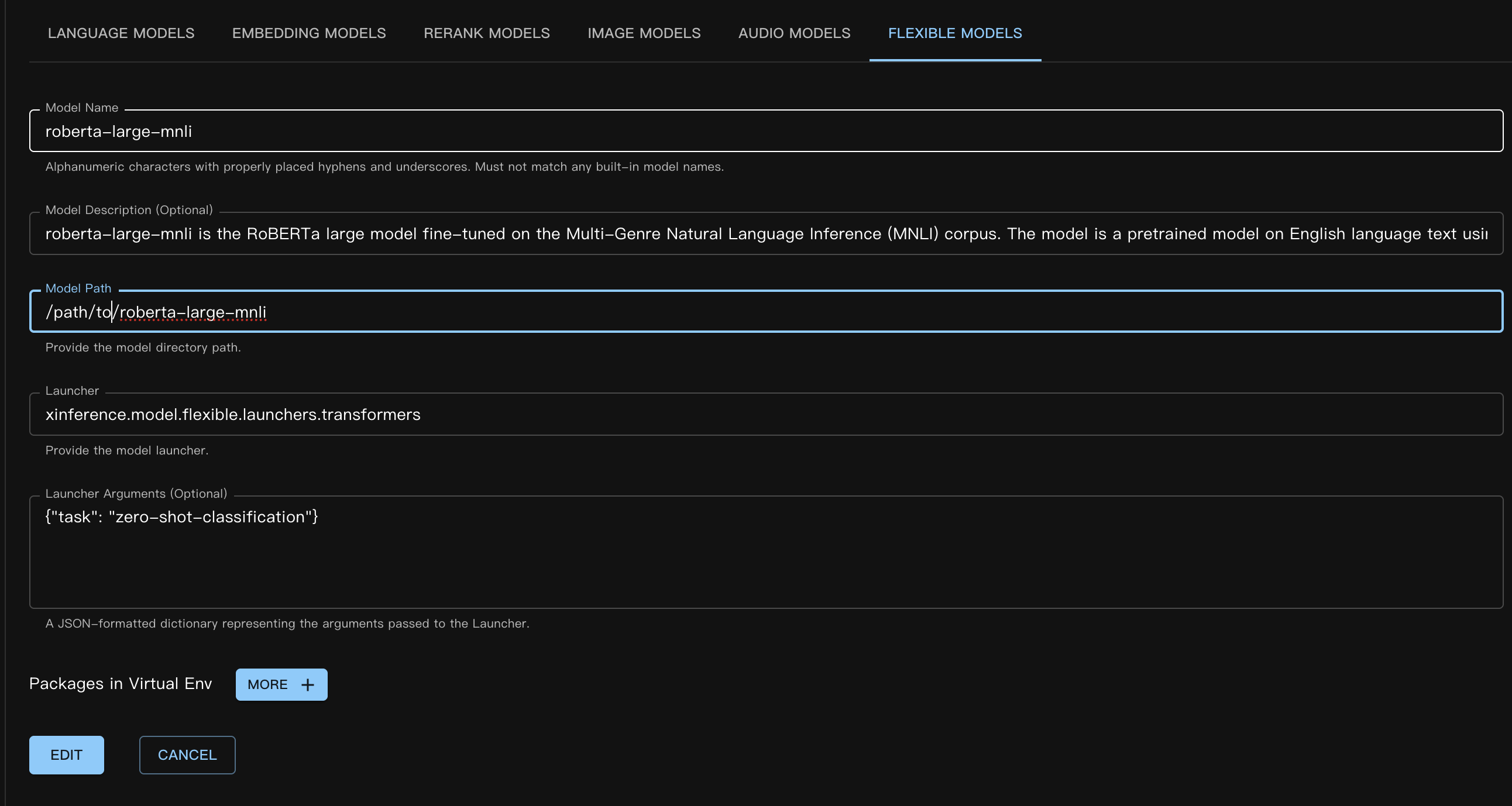
Il corrispondente file JSON del modello personalizzato è il seguente:
{
"model_name": "roberta-large-mnli",
"model_id": null,
"model_revision": null,
"model_hub": "huggingface",
"model_description": "roberta-large-mnli is the RoBERTa large model fine-tuned on the Multi-Genre Natural Language Inference (MNLI) corpus. The model is a pretrained model on English language text using a masked language modeling (MLM) objective.",
"model_uri": "/path/to/roberta-large-mnli",
"launcher": "xinference.model.flexible.launchers.transformers",
"launcher_args": "{\"task\": \"zero-shot-classification\"}",
"virtualenv": {
"packages": [],
"inherit_pip_config": true,
"index_url": null,
"extra_index_url": null,
"find_links": null,
"trusted_host": null,
"no_build_isolation": null
},
"is_builtin": false
}
Vedi la sezione register_custom_model per sapere come registrare un modello tramite codice o riga di comando.
Successivamente, nell’interfaccia Web UI, seleziona Modello di avvio / Modello personalizzato / Modello flessibile per caricare il modello. Il processo di caricamento è lo stesso degli altri tipi di modello.
Quando si utilizza la riga di comando, ricordarsi di specificare il parametro --model-type flexible.
Una volta che il modello viene caricato con successo, possiamo eseguire l’inferenza nei seguenti modi.
curl -X 'POST' \
'http://<XINFERENCE_HOST>:<XINFERENCE_PORT>/v1/flexible/infers' \
-H 'accept: application/json' \
-H 'Content-Type: application/json' \
-d '{
"model": "roberta-large-mnli",
"args": [
"one day I will see the world",
["travel", "cooking", "dancing"]
]
}'
from xinference.client import Client
client = Client("http://<XINFERENCE_HOST>:<XINFERENCE_PORT>")
model = client.get_model("roberta-large-mnli")
sequence_to_classify = "one day I will see the world"
candidate_labels = ['travel', 'cooking', 'dancing']
model.infer(sequence_to_classify, candidate_labels)
{"sequence":"one day I will see the world","labels":["travel","cooking","dancing"],"scores":[0.9799638986587524,0.010605016723275185,0.009431036189198494]}
Modello Pipeline di ModelScope#
ModelScope Pipeline è molto simile al modello Huggingface, l’unica differenza sta nel launcher utilizzato.
Prendiamo come esempio un modello di classificazione zero-shot su ModelScope. Il modello è iic/nlp_structbert_zero-shot-classification_chinese-base.
Qui abbiamo utilizzato la funzionalità di ambiente virtuale del modello di Xinference. Poiché il modello utilizzato in questo esempio richiede transformers==4.50.3 per funzionare correttamente, per isolare l’ambiente di esecuzione abbiamo utilizzato l”ambiente virtuale durante la registrazione del modello.
La sintassi per specificare pacchetti personalizzati durante la registrazione del modello è la stessa dei pacchetti normali, ma ci sono alcuni casi speciali. Poiché l’ambiente virtuale si basa ancora sul sito-packages dell’interprete Python in esecuzione con Xinference, dobbiamo includere esplicitamente #system_numpy#. Il nome del pacchetto deve essere racchiuso tra #system_xx# per garantire che l’ambiente virtuale, quando creato, sia coerente con l’ambiente di base; in caso contrario, si potrebbero facilmente verificare errori di runtime.
Modalità di registrazione (Web UI):
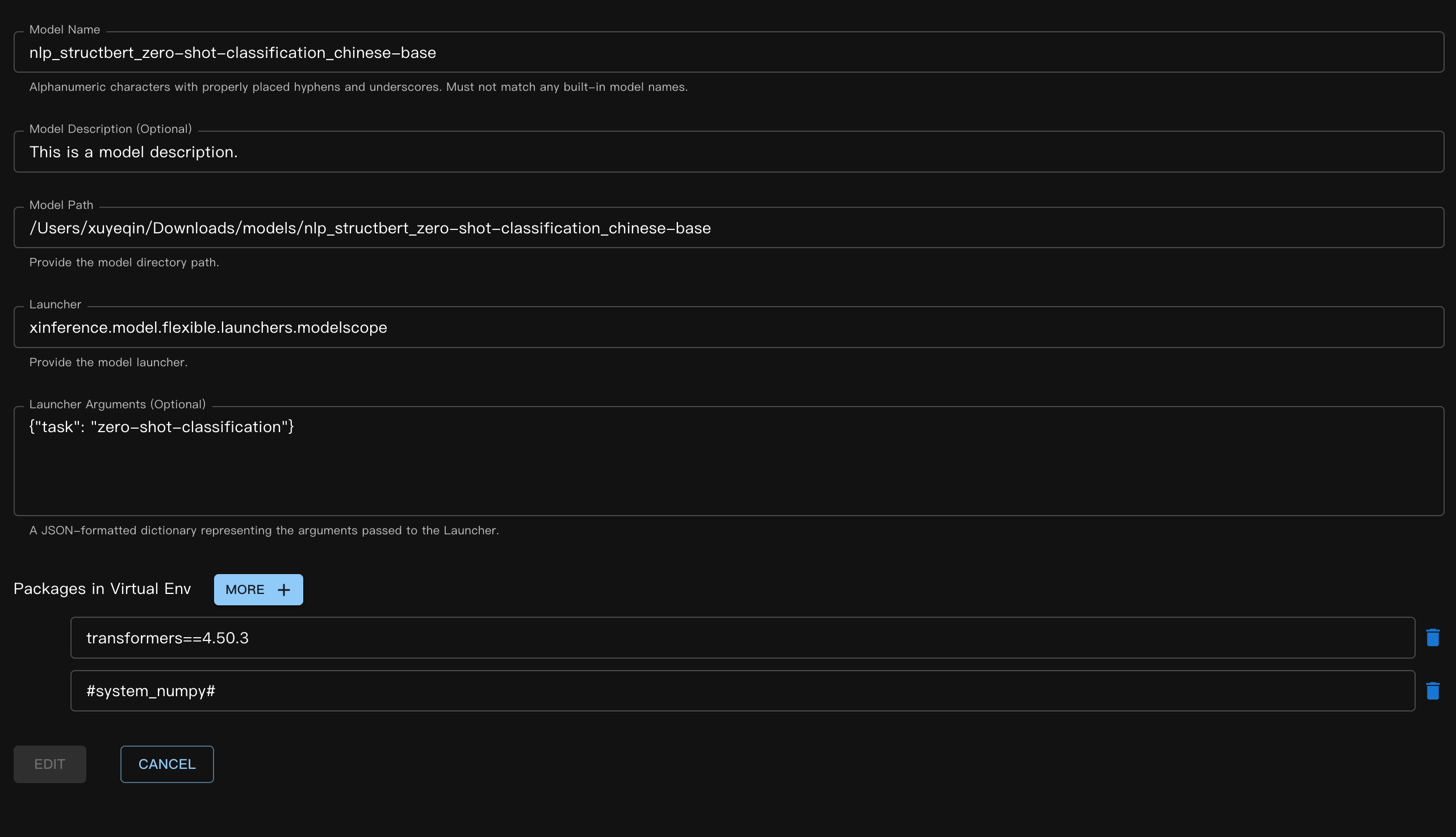
File JSON corrispondente:
{
"model_name": "nlp_structbert_zero-shot-classification_chinese-base",
"model_id": null,
"model_revision": null,
"model_hub": "huggingface",
"model_description": "This is a model description.",
"model_uri": "/Users/xuyeqin/Downloads/models/nlp_structbert_zero-shot-classification_chinese-base",
"launcher": "xinference.model.flexible.launchers.modelscope",
"launcher_args": "{\"task\": \"zero-shot-classification\"}",
"virtualenv": {
"packages": [
"transformers==4.50.3",
"#system_numpy#"
],
"inherit_pip_config": true,
"index_url": "https://mirrors.tuna.tsinghua.edu.cn/pypi/web/simple",
"extra_index_url": null,
"find_links": null,
"trusted_host": null,
"no_build_isolation": null
},
"is_builtin": false
}
Inferenza del modello
curl -X 'POST' \
'http://<XINFERENCE_HOST>:<XINFERENCE_PORT>/v1/flexible/infers' \
-H 'accept: application/json' \
-H 'Content-Type: application/json' \
-d '{
"model": "nlp_structbert_zero-shot-classification_chinese-base",
"args": [
"世界那么大,我想去看看"
],
"candidate_labels": ["家居", "旅游", "科技", "军事", "游戏", "故事"]
}'
from xinference.client import Client
client = Client("http://<XINFERENCE_HOST>:<XINFERENCE_PORT>")
model = client.get_model("nlp_structbert_zero-shot-classification_chinese-base")
labels = ['家居', '旅游', '科技', '军事', '游戏', '故事']
sentence = '世界那么大,我想去看看'
model.infer(sentence, candidate_labels=labels)
{"labels":["旅游","故事","游戏","家居","科技","军事"],"scores":[0.5115892291069031,0.1660086065530777,0.11971458047628403,0.08431519567966461,0.06298774480819702,0.05538458004593849]}%
YOLO#
YOLO è un modello popolare di rilevamento di oggetti in tempo reale, ampiamente utilizzato in scenari di rilevamento di immagini e analisi video.
Prima di tutto, scarica i pesi YOLO. Qui prendiamo come esempio il file yolov11s.pt.
File JSON della definizione del modello:
{
"model_name": "yolo11s",
"model_id": null,
"model_revision": null,
"model_hub": "huggingface",
"model_description": "YOLO is a popular real-time object detection model, widely used in image detection and video analysis scenarios.",
"model_uri": "/Users/xuyeqin/Downloads/models/yolo11s.pt",
"launcher": "xinference.model.flexible.launchers.yolo",
"launcher_args": "{}",
"virtualenv": {
"packages": [
"ultralytics",
"#system_numpy#"
],
"inherit_pip_config": true,
"index_url": "https://mirrors.tuna.tsinghua.edu.cn/pypi/web/simple",
"extra_index_url": null,
"find_links": null,
"trusted_host": null,
"no_build_isolation": null
},
"is_builtin": false
}
Inferenza del modello
import requests
from PIL import Image
import io
import base64
from xinference.client import Client
client = Client("http://<XINFERENCE_HOST>:<XINFERENCE_PORT>")
model = client.get_model("yolo11s")
url = "https://ultralytics.com/images/bus.jpg"
response = requests.get(url)
response.raise_for_status()
img = Image.open(io.BytesIO(response.content))
buffered = io.BytesIO()
img.save(buffered, format="JPEG")
img_bytes = buffered.getvalue()
img_base64 = base64.b64encode(img_bytes).decode('utf-8')
model.infer(source=img_base64)
[[{'name': 'bus',
'class': 5,
'confidence': 0.93653,
'box': {'x1': 13.9521, 'y1': 227.0665, 'x2': 800.17688, 'y2': 739.13965}},
{'name': 'person',
'class': 0,
'confidence': 0.89741,
'box': {'x1': 669.89709,
'y1': 389.82065,
'x2': 809.58966,
'y2': 879.65491}},
{'name': 'person',
'class': 0,
'confidence': 0.88205,
'box': {'x1': 52.37262, 'y1': 397.83792, 'x2': 248.506, 'y2': 905.98212}},
{'name': 'person',
'class': 0,
'confidence': 0.8706,
'box': {'x1': 222.58685,
'y1': 405.93442,
'x2': 345.02032,
'y2': 859.52789}},
{'name': 'person',
'class': 0,
'confidence': 0.66505,
'box': {'x1': 0.28522, 'y1': 548.60931, 'x2': 81.25904, 'y2': 871.59076}}]]
Scrittura di un modello flessibile personalizzato#
Innanzitutto, abbiamo implementato un semplice launcher personalizzato per la valutazione delle emozioni. In questo esempio, non utilizziamo alcun peso effettivo del modello, quindi la funzione load non esegue alcuna operazione di caricamento del modello.
# my_flexible_model.py
from xinference.model.flexible import FlexibleModel
class RuleBasedSentimentModel(FlexibleModel):
def load(self):
self.pos_words = self.config.get("pos", ["good", "happy", "great"])
self.neg_words = self.config.get("neg", ["bad", "sad", "terrible"])
def infer(self, text: str):
score = 0
words = text.lower().split()
for w in words:
if w in self.pos_words:
score += 1
elif w in self.neg_words:
score -= 1
return {"score": score}
def launcher(model_uid: str, model_spec: FlexibleModel, **kwargs) -> FlexibleModel:
# get model path,
# in this example, we do not use it, so it's empty
model_path = model_spec.model_uri
return RuleBasedSentimentModel(model_uid=model_uid, model_path=model_path, config=kwargs)
Il modello JSON è definito come segue:
{
"model_name": "my-flexible-model",
"model_id": null,
"model_revision": null,
"model_hub": "huggingface",
"model_description": "This is a model description.",
"model_uri": "/path/to/model",
"launcher": "my_flexible_model.launcher",
"launcher_args": "{\"pos\": [\"good\", \"happy\", \"great\", \"nice\"]}",
"virtualenv": {
"packages": [],
"inherit_pip_config": true,
"index_url": null,
"extra_index_url": null,
"find_links": null,
"trusted_host": null,
"no_build_isolation": null
},
"is_builtin": false
}
Qui estendiamo il modello passando un valore personalizzato pos.
Infine, verifichiamo il risultato:
from xinference.client import Client
client = Client("http://127.0.0.1:9997")
model = client.get_model("my-flexible-model")
model.infer("I feel nice and am happy today")
{'score': 2}
Conclusione#
Il launcher di modelli flessibili integrato in Xinference può essere trovato su GitHub. Si accettano contributi per aggiungere il supporto di più modelli di machine learning tradizionali!