Multimodale#
Impara come utilizzare LLM per elaborare immagini e audio.
Visivo#
Con la capacità vision, è possibile far sì che il modello riceva immagini e risponda a domande su di esse. In Xinference, ciò indica che alcuni modelli sono in grado di elaborare input di immagini durante le conversazioni tramite Chat API.
Elenco dei modelli supportati#
I modelli che supportano la funzionalità vision in Xinference sono i seguenti:
qwen-vl-chat
deepseek-vl-chat
omnilmm
cogvlm2
MiniCPM-Llama3-V 2.5
glm-edge-v
Guida rapida#
Il modello può acquisire immagini in due modi principali: passando il link dell’immagine o passando direttamente nella richiesta un’immagine codificata in base64.
Esempio di utilizzo del client OpenAI#
import openai
client = openai.Client(
api_key="cannot be empty",
base_url=f"http://<XINFERENCE_HOST>:<XINFERENCE_PORT>/v1"
)
response = client.chat.completions.create(
model="<MODEL_UID>",
messages=[
{
"role": "user",
"content": [
{"type": "text", "text": "What’s in this image?"},
{
"type": "image_url",
"image_url": {
"url": "http://i.epochtimes.com/assets/uploads/2020/07/shutterstock_675595789-600x400.jpg",
},
},
],
}
],
)
print(response.choices[0])
Carica l’immagine codificata in Base64#
import openai
import base64
# Function to encode the image
def encode_image(image_path):
with open(image_path, "rb") as image_file:
return base64.b64encode(image_file.read()).decode('utf-8')
# Path to your image
image_path = "path_to_your_image.jpg"
# Getting the base64 string
b64_img = encode_image(image_path)
client = openai.Client(
api_key="cannot be empty",
base_url=f"http://<XINFERENCE_HOST>:<XINFERENCE_PORT>/v1"
)
response = client.chat.completions.create(
model="<MODEL_UID>",
messages=[
{
"role": "user",
"content": [
{"type": "text", "text": "What’s in this image?"},
{
"type": "image_url",
"image_url": {
"url": f"data:image/jpeg;base64,{b64_img}",
},
},
],
}
],
)
print(response.choices[0])
Limita il numero di immagini per ogni turno di dialogo#
Per i modelli visivi che utilizzano il backend VLLM, è possibile limitare il numero di immagini elaborabili per ogni turno di dialogo tramite il parametro limit_mm_per_prompt. Questo aiuta a controllare l’uso della memoria e a migliorare le prestazioni.
# Launch model with image count limitation using Python client
from xinference.client import Client
client = Client("http://<XINFERENCE_HOST>:<XINFERENCE_PORT>")
# Launch model and set maximum 4 images per conversation turn
model_uid = client.launch_model(
model_name="qwen2.5-vl-instruct",
model_engine="vLLM",
model_format="pytorch",
quantization="none",
model_size_in_billions=3,
limit_mm_per_prompt="{\"image\": 4}"
)
In alternativa, puoi avviare il modello tramite riga di comando:
# Launch model with image count limitation using CLI
xinference launch \
--model-engine vLLM \
--model-name qwen2.5-vl-instruct \
--size-in-billions 3 \
--model-format pytorch \
--quantization none \
--limit_mm_per_prompt "{\"image\":4}"
Per l’interfaccia web, puoi impostare il parametro limit_mm_per_prompt nel modulo del motore vLLM:
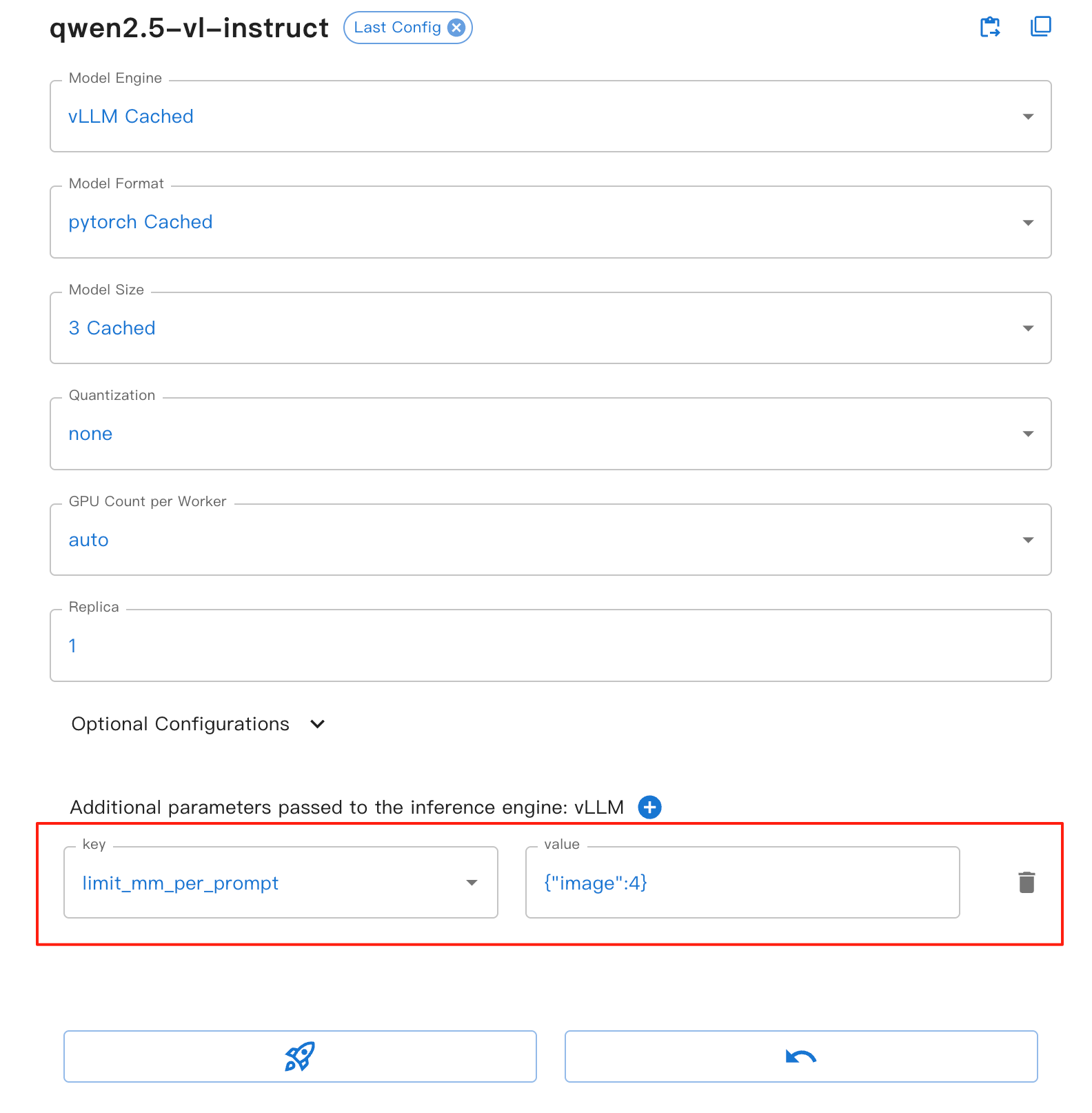
Questo parametro offre i seguenti vantaggi:
image: imposta il numero massimo di immagini consentite per turno di dialogo.
Aiuta a prevenire l’overflow di memoria, specialmente durante l’elaborazione di più immagini.
Migliorare la stabilità e le prestazioni dell’inferenza del modello
Applicabile a tutti i modelli visivi basati su VLLM
Nota
Il parametro limit_mm_per_prompt è effettivo solo quando si utilizza il backend VLLM. Se il tuo modello utilizza un altro backend, questo parametro verrà ignorato.
Puoi trovare altri esempi delle capacità di vision nei notebook del tutorial.
Impara a utilizzare le capacità visive dei LLM con un esempio di qwen-vl-chat.
audio#
Attraverso la funzionalità «audio», il tuo modello può ricevere tracce audio ed eseguire analisi audio o generare direttamente risposte testuali basate su comandi vocali. In Xinference, ciò significa che alcuni modelli sono in grado di gestire input audio durante le conversazioni tramite Chat API.
Elenco dei modelli supportati#
La funzione «audio» in Xinference supporta i seguenti modelli:
Guida rapida#
L’audio può essere fornito al modello in due modi principali: tramite un collegamento all’immagine o passando direttamente l’URL dell’audio nella richiesta.
Chat con audio#
from xinference.client import Client
client = Client("http://<XINFERENCE_HOST>:<XINFERENCE_PORT>")
model = client.get_model(<MODEL_UID>)
messages = [
{"role": "system", "content": "You are a helpful assistant."},
{
"role": "user",
"content": [
{
"type": "audio",
"audio_url": "https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen2-Audio/audio/glass-breaking-151256.mp3",
},
{"type": "text", "text": "What's that sound?"},
],
},
{"role": "assistant", "content": "It is the sound of glass shattering."},
{
"role": "user",
"content": [
{"type": "text", "text": "What can you do when you hear that?"},
],
},
{
"role": "assistant",
"content": "Stay alert and cautious, and check if anyone is hurt or if there is any damage to property.",
},
{
"role": "user",
"content": [
{
"type": "audio",
"audio_url": "https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen2-Audio/audio/1272-128104-0000.flac",
},
{"type": "text", "text": "What does the person say?"},
],
},
]
print(model.chat(messages))