Motore di inferenza#
Xinference supporta diversi motori di inferenza per modelli differenti. Dopo che l’utente ha selezionato un modello, Xinference sceglierà automaticamente il motore appropriato.
llama.cpp#
Xinference attualmente supporta xllamacpp sviluppato dal team di Xinference come backend per l’esecuzione di llama.cpp. llama.cpp è sviluppato sulla base della libreria tensoriale ggml e supporta l’inferenza dei modelli della serie LLaMA e delle loro varianti.
Avvertimento
A partire da Xinference v1.5.0, xllamacpp è diventata l’opzione predefinita per llama.cpp, e llama-cpp-python è stato deprecato; a partire da Xinference v1.6.0, llama-cpp-python è stato rimosso.
Fare riferimento alla definizione della struttura common_params in common.h <https://github.com/ggml-org/llama.cpp/blob/master/common/common.h>`_ di ``llama.cpp per impostare i parametri.
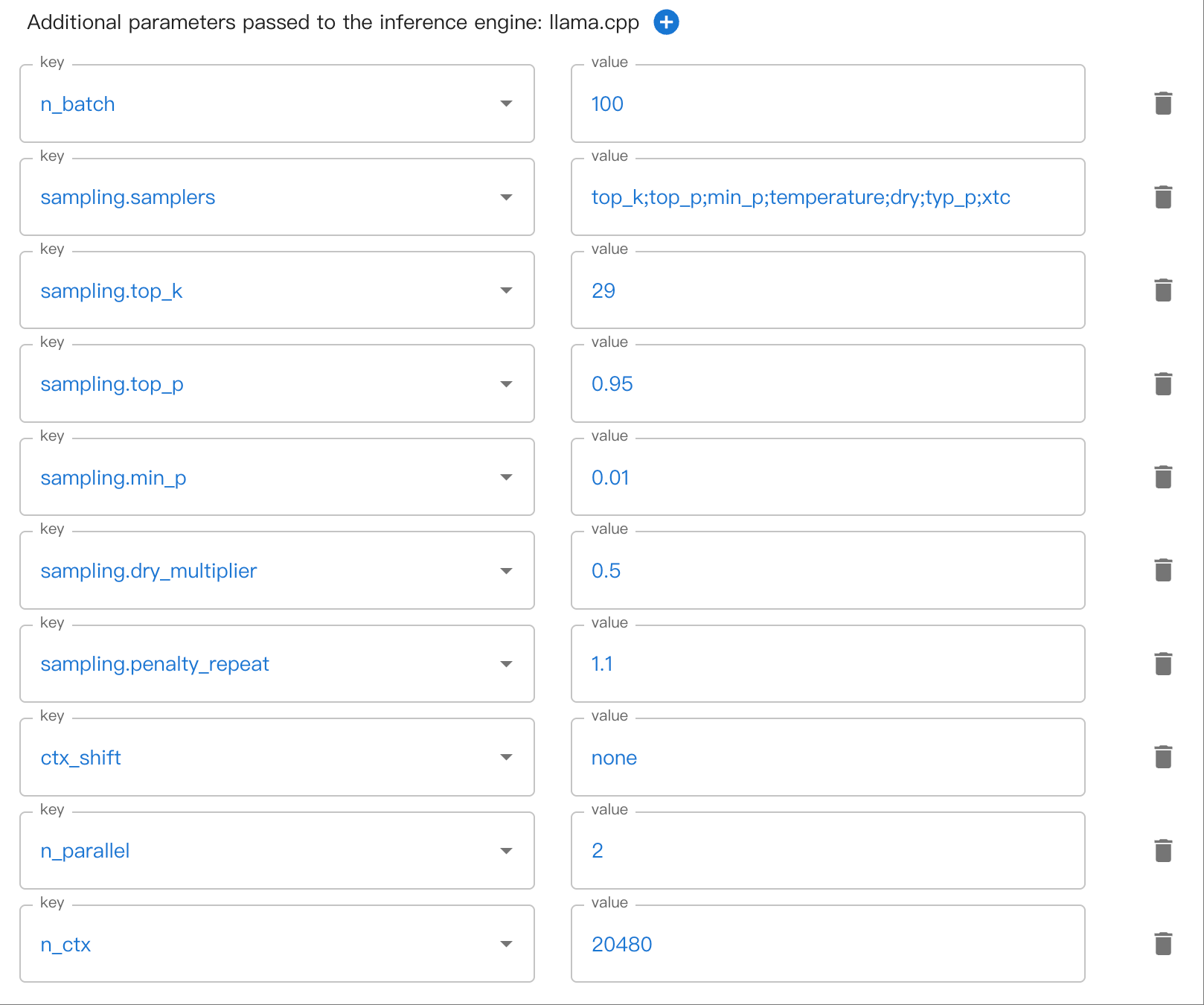
Possono esserci parametri annidati su più livelli. Ad esempio, sampling.top_k. Utilizzare . per separare i parametri annidati.
Ecco un esempio di impostazione dei parametri di campionamento annidato nella WebUI:
NGL automatico#
Added in version v1.6.1: A partire dalla v1.6.1, se n-gpu-layers non viene specificato (valore predefinito -1), la stima del numero di layer GPU viene attivata automaticamente.
Questa funzionalità può impostare automaticamente il numero di layer GPU (NGL) per il backend llama.cpp. Si noti che non si tratta di un calcolo preciso, quindi il risultato di -ngl potrebbe non essere ottimale ed è ancora possibile incontrare errori di memoria GPU insufficiente.
Al momento NGL automatico non ha supporto ufficiale. Fare riferimento al seguente issue per maggiori dettagli:
La nostra implementazione si basa sull’NGL automatico di Ollama, ma presenta alcune differenze:
Utilizziamo le informazioni del dispositivo fornite da xllamacpp.
Abbiamo rimosso il supporto per alcune architetture poco comuni, per le quali veniva utilizzata la logica di calcolo predefinita.
Se il NGL automatico fallisce, proviamo a caricare tutto sulla GPU.
Non supportiamo l’incorporazione del proiettore multimodale all’interno del modello GGUF, poiché questo formato di modello è ancora in fase sperimentale.
Domande Frequenti#
Server error: {“code”: 500, “message”: “failed to process image”, “type”: “server_error”}
Log del server:
encoding image or slice... slot update_slots: id 0 | task 0 | kv cache rm [10, end) srv process_chun: processing image... ggml_metal_graph_compute: command buffer 0 failed with status 5 error: Internal Error (0000000e:Internal Error) clip_image_batch_encode: ggml_backend_sched_graph_compute failed with error -1 failed to encode image srv process_chun: image processed in 2288 ms mtmd_helper_eval failed with status 1 slot update_slots: id 0 | task 0 | failed to process image, res = 1
Possibilmente causato da memoria insufficiente. Puoi provare a ridurre
n_ctxper risolvere.Server error: {“code”: 400, “message”: “the request exceeds the available context size. try increasing the context size or enable context shift”, “type”: “invalid_request_error”}
Se stai utilizzando la funzionalità multimodale,
ctx_shiftverrà disattivato per impostazione predefinita. Prova ad aumentaren_ctxo ridurren_parallelper incrementare la dimensione del contesto per ogni slot.Server error: {“code”: 500, “message”: “Input prompt is too big compared to KV size. Please try increasing KV size.”, “type”: “server_error”}
Log del server:
ggml_metal_graph_compute: command buffer 1 failed with status 5 error: Insufficient Memory (00000008:kIOGPUCommandBufferCallbackErrorOutOfMemory) graph_compute: ggml_backend_sched_graph_compute_async failed with error -1 llama_decode: failed to decode, ret = -3 srv update_slots: failed to decode the batch: KV cache is full - try increasing it via the context size, i = 0, n_batch = 2048, ret = -3
Potrebbe essere causato dal fallimento della creazione della cache KV. Puoi risolvere riducendo
n_ctx, aumentandon_parallelo regolando il parametron_gpu_layersper caricare parte del modello sulla GPU. Nota che se gestisci solo richieste di inferenza seriale, aumentaren_parallelnon porterà miglioramenti delle prestazioni.
transformers#
Transformers supporta la stragrande maggioranza dei modelli di nuova uscita. È il motore predefinito utilizzato per i modelli in formato Pytorch.
vLLM#
vLLM è un motore di inferenza per modelli linguistici di grandi dimensioni molto efficiente e facile da usare.
vLLM ha le seguenti caratteristiche:
Latenza di inferenza leader
Usare PagedAttention per gestire in modo efficiente la memoria delle chiavi e dei valori dell’attenzione
Elaborazione in batch continua delle richieste in arrivo
Kernel CUDA ottimizzati
Quando vengono soddisfatte le seguenti condizioni, Xinference seleziona automaticamente vLLM come motore di inferenza:
Il formato del modello è
pytorch,gptq,awq,fp4,fp8oppurebnb.Quando il formato del modello è
pytorch, l’opzione di quantizzazione deve esserenone.Quando il formato del modello è
awq, l’opzione di quantizzazione deve essereInt4.Quando il formato del modello è
gptq, le opzioni di quantizzazione devono essereInt3,Int4oInt8.Il sistema operativo è Linux e dispone di almeno un dispositivo che supporta CUDA.
I campi
model_familydei modelli personalizzati emodel_namedei modelli integrati sono elencati nell’elenco di supporto di vLLM.
Attualmente, i modelli supportati includono:
code-llama,code-llama-instruct,code-llama-python,deepseek,deepseek-chat,deepseek-coder,deepseek-coder-instruct,deepseek-r1-distill-llama,gorilla-openfunctions-v2,HuatuoGPT-o1-LLaMA-3.1,llama-2,llama-2-chat,llama-3,llama-3-instruct,llama-3.1,llama-3.1-instruct,llama-3.3-instruct,minicpm5-1b,tiny-llama,wizardcoder-python-v1.0,wizardmath-v1.0,Yi,Yi-1.5,Yi-1.5-chat,Yi-1.5-chat-16k,Yi-200k,Yi-chatcodestral-v0.1,mistral-instruct-v0.1,mistral-instruct-v0.2,mistral-instruct-v0.3,mistral-large-instruct,mistral-nemo-instruct,mistral-v0.1,openhermes-2.5,seallm_v2Baichuan-M2,codeqwen1.5,codeqwen1.5-chat,deepseek-r1-distill-qwen,DianJin-R1,fin-r1,HuatuoGPT-o1-Qwen2.5,KAT-V1,marco-o1,qwen1.5-chat,qwen2-instruct,qwen2.5,qwen2.5-coder,qwen2.5-coder-instruct,qwen2.5-instruct,qwen2.5-instruct-1m,qwenLong-l1,QwQ-32B,QwQ-32B-Preview,seallms-v3,skywork-or1,skywork-or1-preview,XiYanSQL-QwenCoder-2504llama-3.2-vision,llama-3.2-vision-instructbaichuan-2,baichuan-2-chatInternLM2ForCausalLMqwen-chatmixtral-8x22B-instruct-v0.1,mixtral-instruct-v0.1,mixtral-v0.1cogagentglm-edge-chat,glm4-chat,glm4-chat-1mcodegeex4,glm-4vseallm_v2.5orion-chatqwen1.5-moe-chat,qwen2-moe-instructCohereForCausalLMdeepseek-v2-chat,deepseek-v2-chat-0628,deepseek-v2.5,deepseek-vl2deepseek-prover-v2,deepseek-r1,deepseek-r1-0528,deepseek-v3,deepseek-v3-0324,Deepseek-V3.1,moonlight-16b-a3b-instructdeepseek-r1-0528-qwen3,qwen3minicpm3-4binternlm3-instructgemma-3-1b-itglm4-0414minicpm-2b-dpo-bf16,minicpm-2b-dpo-fp16,minicpm-2b-dpo-fp32,minicpm-2b-sft-bf16,minicpm-2b-sft-fp32,minicpm4Ernie4.5Qwen3-Coder,Qwen3-Instruct,Qwen3-Thinkingglm-4.5,GLM-4.6,GLM-4.7gpt-ossseed-ossQwen3-Next-Instruct,Qwen3-Next-ThinkingDeepSeek-V3.2,DeepSeek-V3.2-ExpMiniMax-M2,MiniMax-M2.5,MiniMax-M2.7GLM-4.7-Flashglm-5,glm-5.1DeepSeek-V4-Flash,DeepSeek-V4-Pro
SGLang#
SGLang è dotato di un runtime di inferenza ad alte prestazioni basato su RadixAttention. Accelera significativamente l’esecuzione di programmi LLM complessi riutilizzando automaticamente la cache KV tra più chiamate. Supporta inoltre altre tecniche di inferenza comuni, come il batch continuo e l’elaborazione parallela dei tensori.
MLX#
MLX fornisce un modo per eseguire LLM in modo efficiente sui chip Apple Silicon. Quando il modello è disponibile in formato MLX, si consiglia agli utenti Mac con chip Apple Silicon di utilizzare il motore MLX.