Distributed inference#
Alcuni modelli linguistici, inclusi DeepSeek V3, DeepSeek R1 e altri, sono troppo grandi per essere adattati alla GPU di una singola macchina. Xinference supporta l’esecuzione di questi modelli su più macchine.
Added in version v1.3.0.
Motori supportati#
Ora, Xinference supporta i seguenti motori per eseguire modelli su più worker.
SGLang (supportato in v1.3.0)
vLLM (supportato in v1.4.1)
MLX (supporto dalla v1.7.1) attualmente non supporta tutti i modelli in modalità distribuita. Al momento sono supportati i seguenti tipi di modelli. Se hai altre esigenze, ti invitiamo a inviare una issue su GitHub all’indirizzo xorbitsai/inference#issues per richiedere supporto.
DeepSeek v3 e R1
Qwen2.5-instruct e altri modelli con la stessa architettura.
Qwen3 e altri modelli con la stessa architettura del modello.
Qwen3-moe e altri modelli con la stessa architettura del modello.
Utilizzo#
Innanzitutto, sono necessari almeno 2 nodi di lavoro per supportare l’inferenza distribuita. Fare riferimento a Esecuzione di Xinference in un cluster per creare un cluster Xinference composto da un nodo supervisor e nodi di lavoro.
vLLM (v0.11.0+) Note: A partire dalla versione vLLM v0.11.0, la distribuzione distribuita con vLLM richiede Xinference >= v1.17.1. Oltre al parametro originale --n-worker, è necessario impostare anche i parametri tensor_parallel_size (impostarlo al numero di GPU) e pipeline_parallel_size=1 durante l’avvio del modello.
Poi, se stai utilizzando l’interfaccia web, seleziona il numero desiderato di macchine come worker count nella configurazione opzionale; se stai utilizzando la riga di comando, aggiungi --n-worker <numero di macchine> quando avvii il modello. Il modello verrà avviato di conseguenza su più nodi di lavoro.
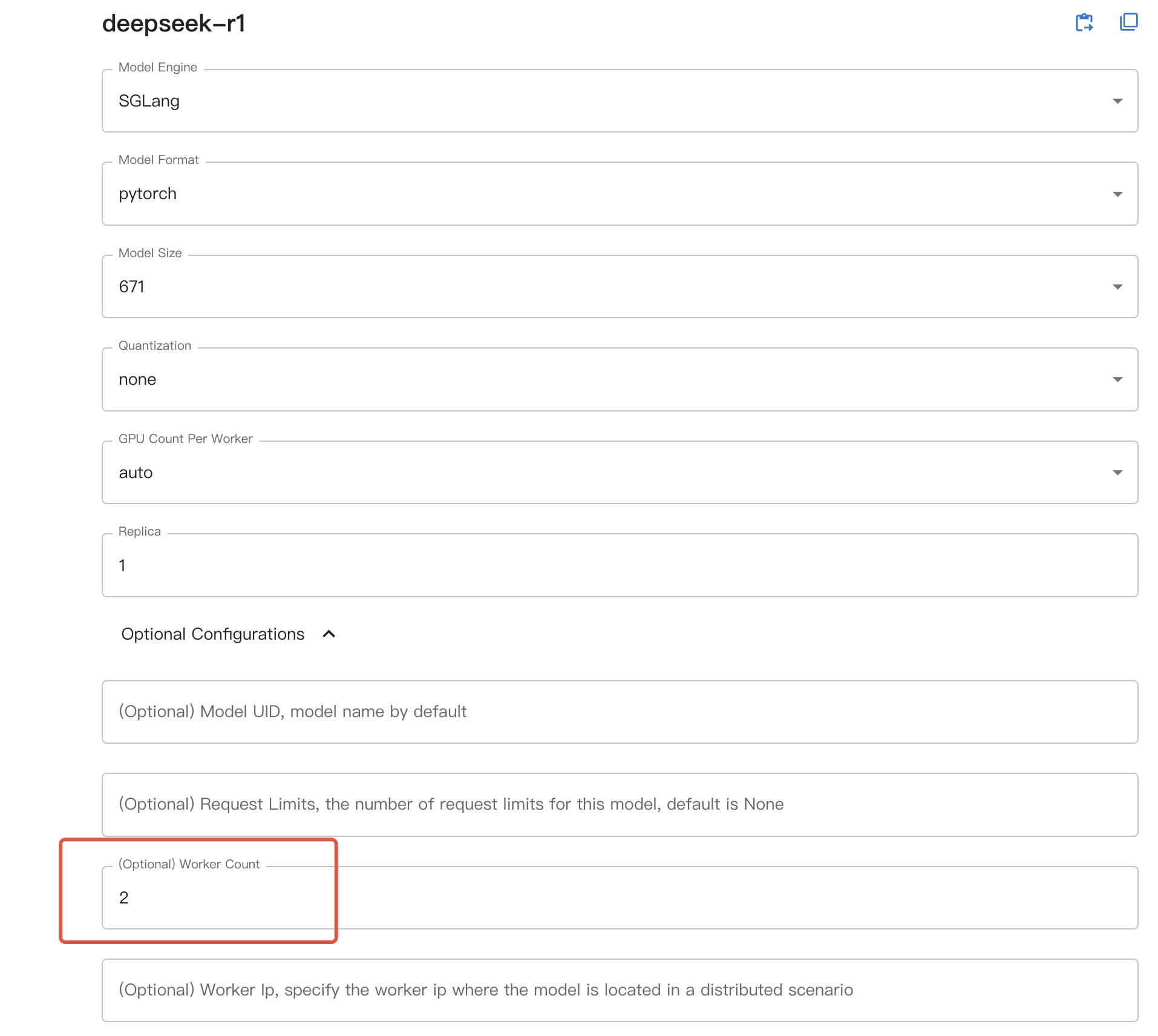
Quando si utilizza l’inferenza distribuita, GPU count nell’interfaccia Web UI o --n-gpu nella riga di comando ora rappresentano il numero di GPU per ciascun nodo di lavoro.