Guida al caricamento dei modelli#
Questo documento ha lo scopo di fornire una descrizione delle funzionalità di caricamento del modello.
Copia#
Le copie vengono utilizzate per specificare il numero di istanze del modello da caricare. Ad esempio, se hai due GPU e ciascuna scheda può contenere una copia del modello, puoi impostare il numero di copie su 2. In questo modo, due istanze identiche del modello verranno distribuite su queste due GPU. Xinference bilancerà automaticamente il carico, assicurando che le richieste vengano distribuite uniformemente tra le schede. Per l’utente, il modello rimane visibile come un unico elemento, migliorando significativamente l’utilizzo complessivo delle risorse.
Distribuzione multi-istanza della versione precedente:
Quando si dispone di più schede GPU, ciascuna può ospitare un’istanza del modello. In questo caso, è possibile impostare il numero di istanze pari al numero di GPU. Ad esempio:
2 GPU, 2 istanze: ciascuna GPU esegue un’istanza del modello.
4 GPU, 4 istanze: su ogni GPU viene eseguita un’istanza del modello
Added in version v1.15.0.
Introduci una nuova variabile d’ambiente:
XINFERENCE_ALLOW_MULTI_REPLICA_PER_GPU
Controlla se abilitare la funzione multi-copia su singola GPU, valore predefinito: 1
Nuova funzionalità: distribuzione intelligente delle istanze
Replica singola GPU
Nuovo supporto: possibilità di eseguire più copie del modello anche con una sola GPU.
Scenario: disponi di una GPU con memoria video abbondante.
Configurazione: Numero di repliche = 3, Numero di GPU = 1
Risultato: 3 istanze del modello, in esecuzione sulla stessa GPU, condividono le risorse della GPU.
Allocazione GPU mista
Allocazione intelligente: il numero di repliche può non essere uguale al numero di GPU; il sistema allocherà in modo intelligente.
Scenario: hai 2 GPU e hai bisogno di 3 repliche.
Configurazione: Numero di repliche=3, Numero di GPU=2
Risultato: GPU0 esegue 2 istanze, GPU1 esegue 1 istanza
Strategia di allocazione mista#
La strategia attuale è Priorità di inattività: lo scheduler cerca sempre di assegnare le repliche alla GPU più inattiva. Utilizzare il parametro XINFERENCE_ENV_LAUNCH_STRATEGY per selezionare la strategia di avvio.
Imposta le variabili d’ambiente#
Added in version v1.8.1.
A volte desideriamo specificare variabili d’ambiente per un modello specifico durante l’esecuzione. A partire dalla v1.8.1, Xinference offre la funzionalità di configurare singolarmente le variabili d’ambiente, senza doverle impostare prima di avviare Xinference.
Per l’interfaccia utente web.
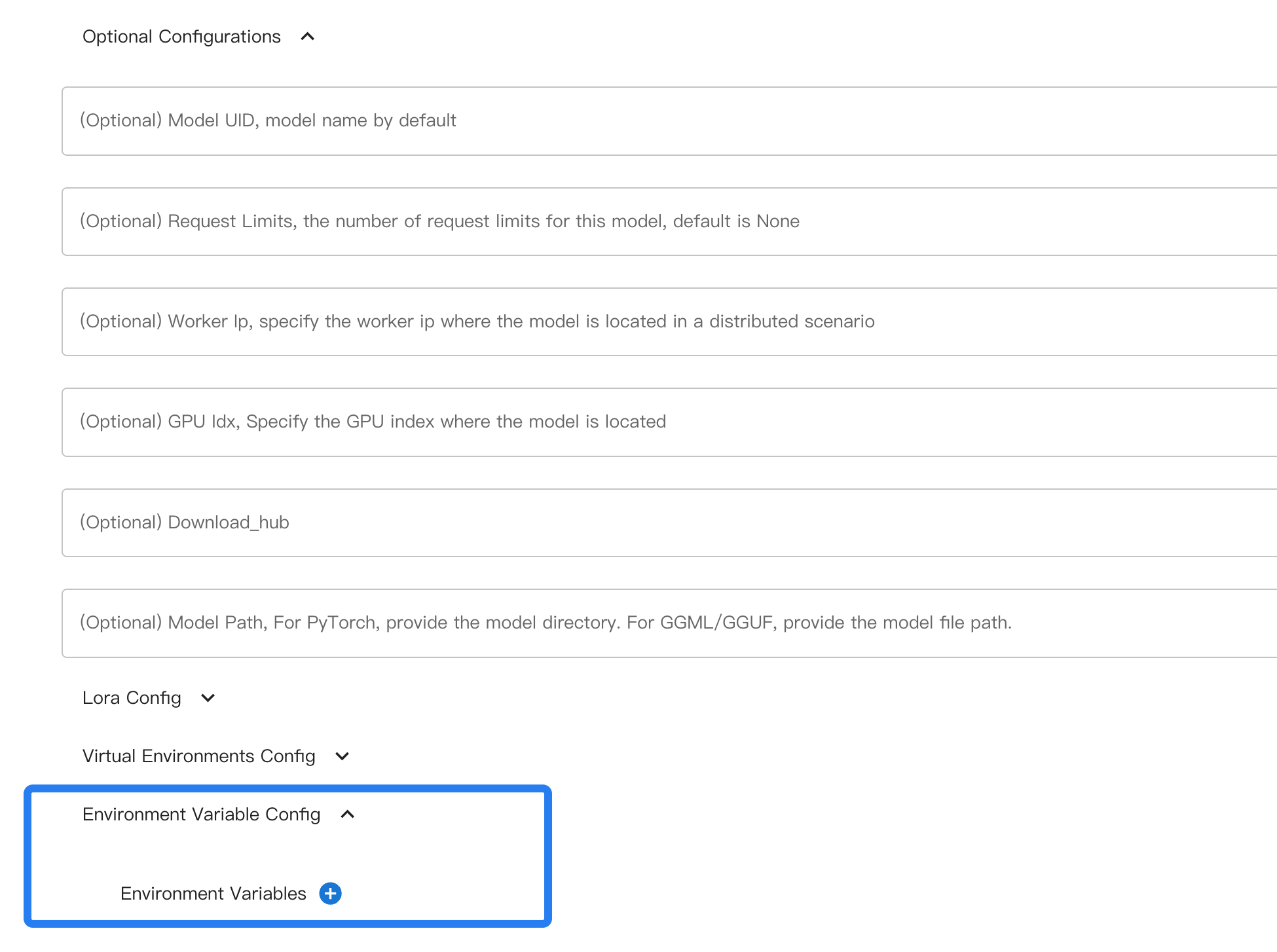
Durante l’uso da riga di comando, specifica le variabili d’ambiente con --env.
Esempio di utilizzo:
xinference launch xxx --env A 0 --env B 1
Prendendo vLLM come esempio, ha due versioni, V1 e V0; per impostazione predefinita, decide automaticamente quale versione utilizzare. Se si desidera forzare l’uso della V0 durante il caricamento del modello impostando VLLM_USE_V1=0, è possibile specificare questa variabile d’ambiente.
Configurazione spazio virtuale modello#
Added in version v1.8.1.
Per questa parte, fare riferimento a switch virtual space and custom dependencies.
Batch / Continuous Batch#
Xinference supporta l’elaborazione batch per aumentare la produttività. Per i modelli di linguaggio di grandi dimensioni basati sul motore transformers, è possibile abilitare la funzione di elaborazione batch continua, configurabile all’avvio tramite variabili d’ambiente.
Impostazioni chiave:
XINFERENCE_BATCH_SIZEeXINFERENCE_BATCH_INTERVALvengono utilizzati per controllare il comportamento standard del batch.XINFERENCE_TEXT_TO_IMAGE_BATCHING_SIZE(modello testo-immagine, quando supportato).
Esempio (Large Language Model, Transformers)
XINFERENCE_BATCH_SIZE=32 XINFERENCE_BATCH_INTERVAL=0.003 xinference-local --log-level debug
xinference launch -e <endpoint> --model-engine transformers -n qwen1.5-chat -s 4 -f pytorch -q none
Esempio (Testo in immagine):
XINFERENCE_TEXT_TO_IMAGE_BATCHING_SIZE=1024*1024 xinference-local --log-level debug
Per informazioni sul comportamento dettagliato, i modelli supportati e le richieste di interruzione, consulta Continuous Batching.
Modalità di pensiero#
Alcuni modelli di inferenza ibrida (ad esempio Qwen3) supportano una modalità di pensiero opzionale. È possibile abilitare questa funzionalità all’avvio tramite il parametro --enable-thinking.
Esempio di utilizzo:
xinference launch -n qwen3-xxx --model-engine vllm --enable-thinking